From Luna to Solar
From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud
Introduction
弹性存储系统(EBS, Elastic Block Storage)要求高可用高速度,并且不同的而硬件配置也使得传统网络协议无法很好地适配。
LUNA:取代内核TCP栈以协调HDD(硬盘)和SSD(固态硬盘)的速度。在计算和存储集群之间的网络使用用户空间的TCP而不是硬件来提高scalability和interoperability。最终发现在性能上有很好的提高。
SOLAR:在LUNA的经验上,使用UDP协议栈实现网络化存储,同时辅之以硬件加速和快速错误恢复。由于网络协议倾向于提供统一的处理方式,而存储硬件的分层结构又带来末端的复杂性,因此SOLAR的主要创新点就在于打破了网络和存储层的边界,将网络包和存储块糅合在一起。
- EBS的数据路径被完全转移到网络部分,独立硬件可以处理而无需牵扯CPU和内存
- 数据块并不需要网络数据报那样要求到达顺序,因此无需维护接受缓冲等
- 轻量级错误检测
- 多路错误恢复(并没有建立TCP那样的端到端连接,错误恢复不影响scalability)
Background
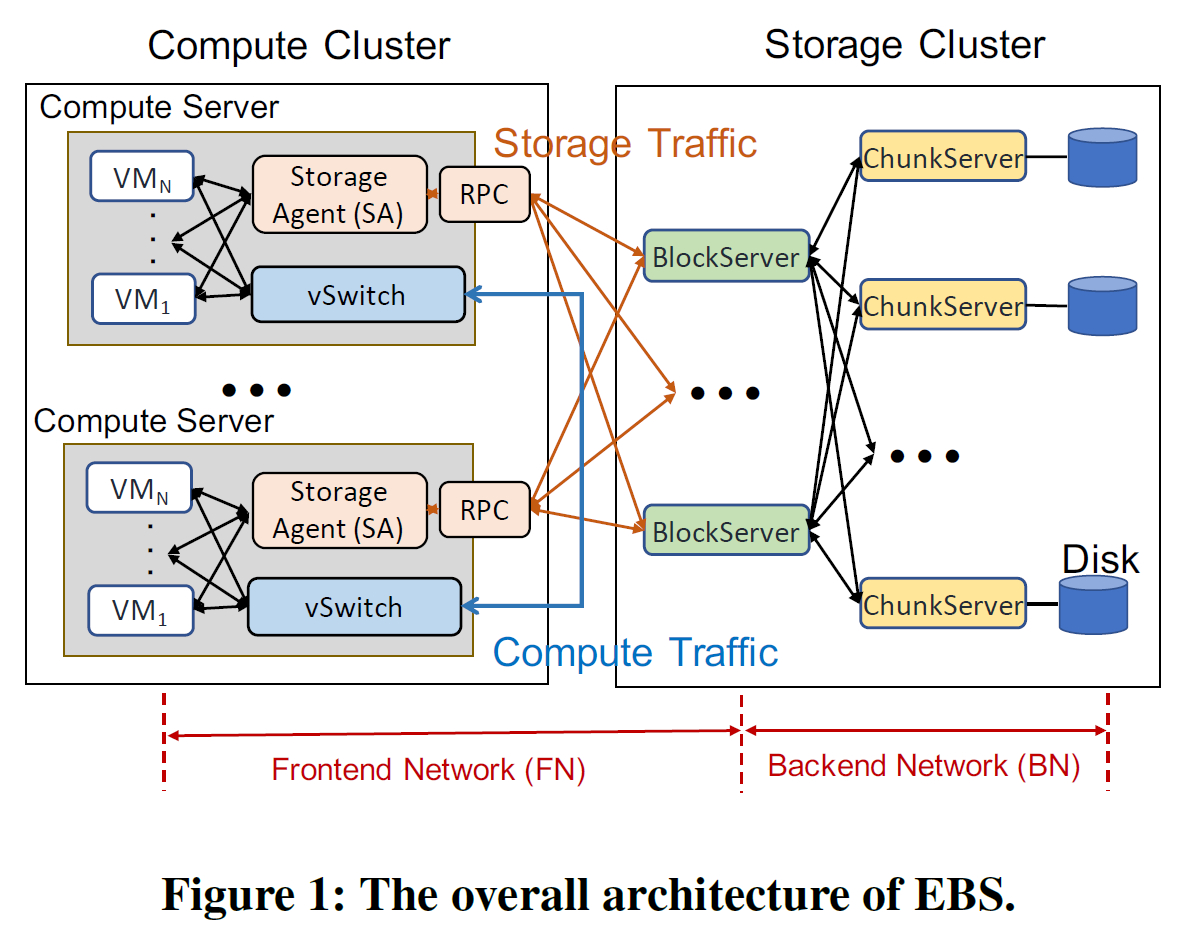
传统EBS网络构造如上图所示,存储服务器和计算服务器的区分使得总体性能高于全部使用通用服务器,另外存储服务器本身也能够被精细化设计从而保证数据安全和效率。本文主要关注Frontend Network(串联同一地区各个集群的前端网络)【Backend Network通常是PoD(point of deliverly)的结构】
Storage Agent(SA)主要维护两个表单:
- Segment Table:虚拟磁盘到物理磁盘数据段的映射
- QoS(quality of service) Table:维护各个虚拟磁盘服务等级和当前使用情况(带宽,IOPS每秒读写次数等)
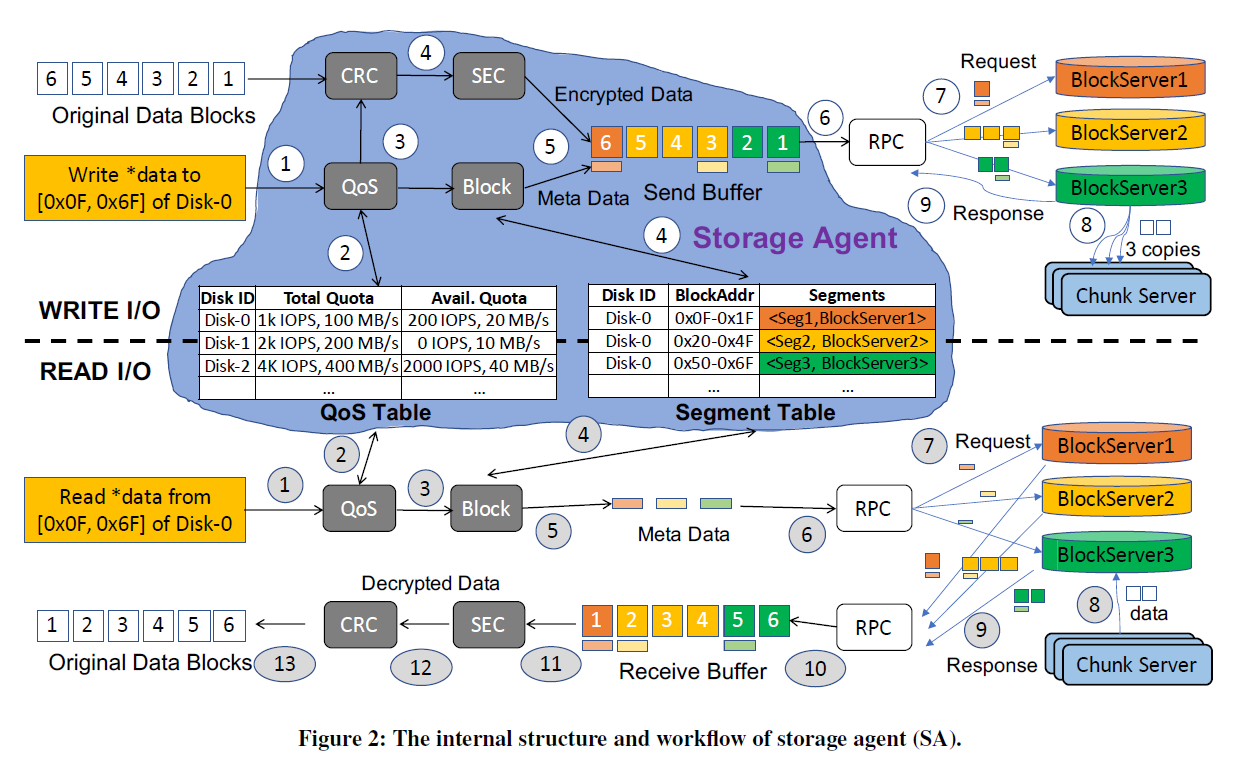
为什么中间要加一个Block/Chunk Server而不是用一些协议进行RDMA(Remote Direct Memory Access)?
- 直接操作磁盘带来的LSM-Tree上的合并等操作与计算专用服务器CPU性能不匹配
- 多个VM操作多个VD带来的一致性问题
- 灵活性、粒度……
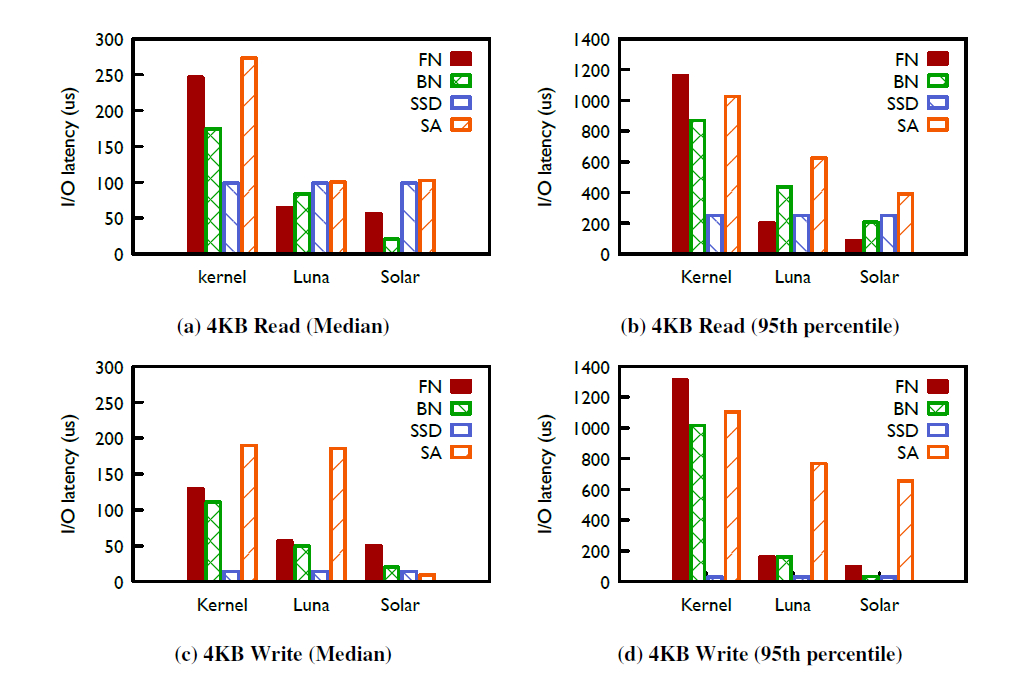
图中是I/O延迟的对比图,可以看到,在使用SSD时,Kernel TCP造成的延迟逐渐成为性能瓶颈(原来用的HDD可能速度更慢),FN/BN/SA都需要去匹配SSD的高速。
这里写速度比读速度快很多的原因是SSD有write cache
LUNA
FN往往连接成百上千的计算节点,同时各个节点的设计往往不太一样,因此对scalability和interoperability有较高的要求。而对BN来说,小集群内硬件的配置大多相同,同时为了控制宕机的影响范围,集群内连接数也不会太多。
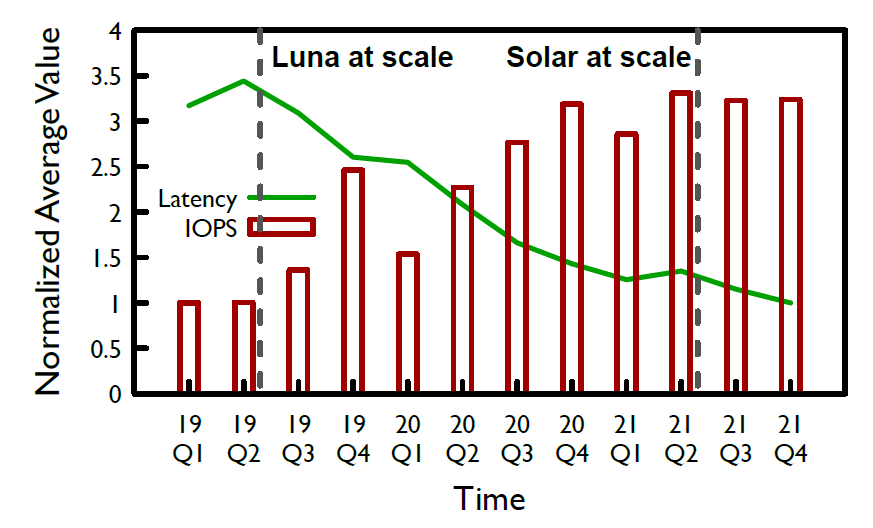
2019年开始LUNA被部署到几乎所有阿里云平台
LUNA的亮点:
NSDI’14 mTCP: a Highly Scalable User-level TCP Stack for Multicore Systems,提供Run-to-Complete实现网络传输的零拷贝
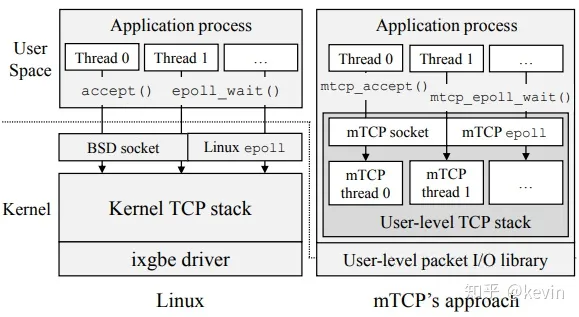
- 读取NIC(网络接口控制器)的数据包由事件驱动而不是轮询,批处理读取
- TCP放到用户态,减少系统调用
- 应用线程和mTCP线程共享buffer【是否是RTC……】
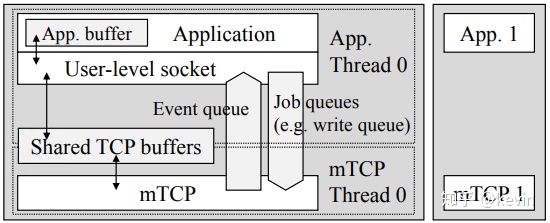
架构类似mTCP,有如下两个拓展
- 通过回收和缓存共享来实现SA到RPC的零拷贝
- lock-free和sharing nothing的线程部署理念,CPU核之间不存在共享和锁,提高并行度
使用LUNA以后:
- SA逐渐转变成性能瓶颈
- 随着网络带宽的进一步提高,将网络栈交由硬件处理变得更加必要
- 错误恢复的时间(通常几秒到几分钟)让人难以接受
SOLAR
bare-metal:将整机提供给客户(可以自行建立多个虚拟机),而非将虚拟机提供给客户
bare-metal cloud:将云基础设施移交到硬件
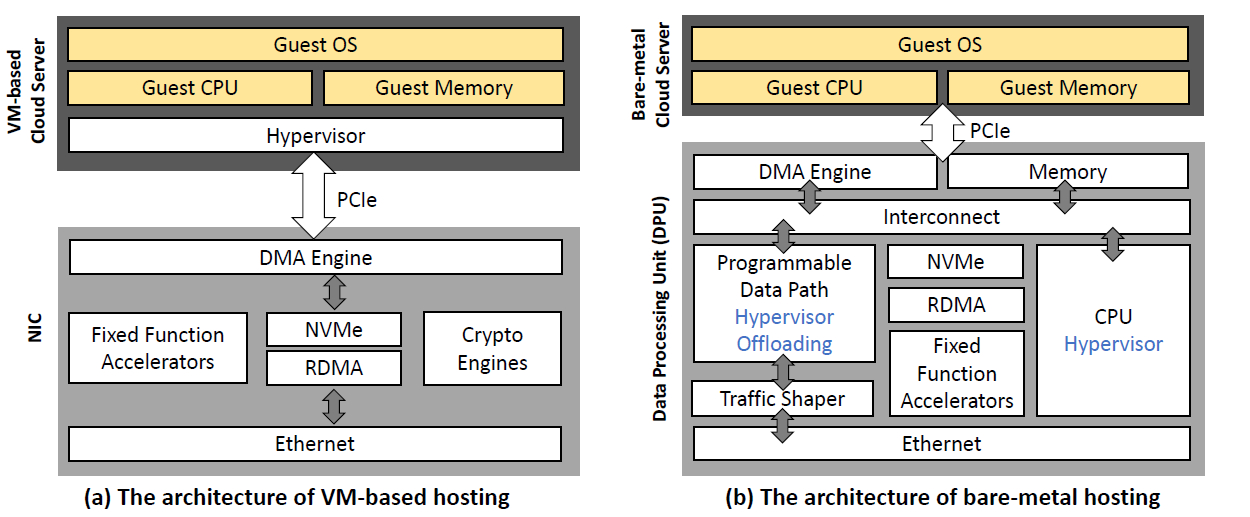
可以看到,DPU(Data Processing Unit)提供CPU(6核以限制能耗)、内存、虚拟化、可编程部件(FPGA/ASIC)以及通过PCIe(外围组件互连快件)进行直接内存访问

LUNA的网络栈和SA都在CPU里,CPU的开销很大。即便使用RDMA将数据访问offload到硬件,SA依然占用了CPU。另外,LUNA还需要经过两次PCIe接口,因此也会被PCIe拖慢一部分性能
SOLAR的设计理念
- 通过将网络栈和SAoffload到硬件上,减少CPU开销,避免PCIe
- 能够检测和通过动态更换路径避免网络不可用
one-block-one-packet
- 更小的buffer【不用考虑失序到达了】
- CPU和内存使用大大降低
- 更少的状态
- 很容易实现
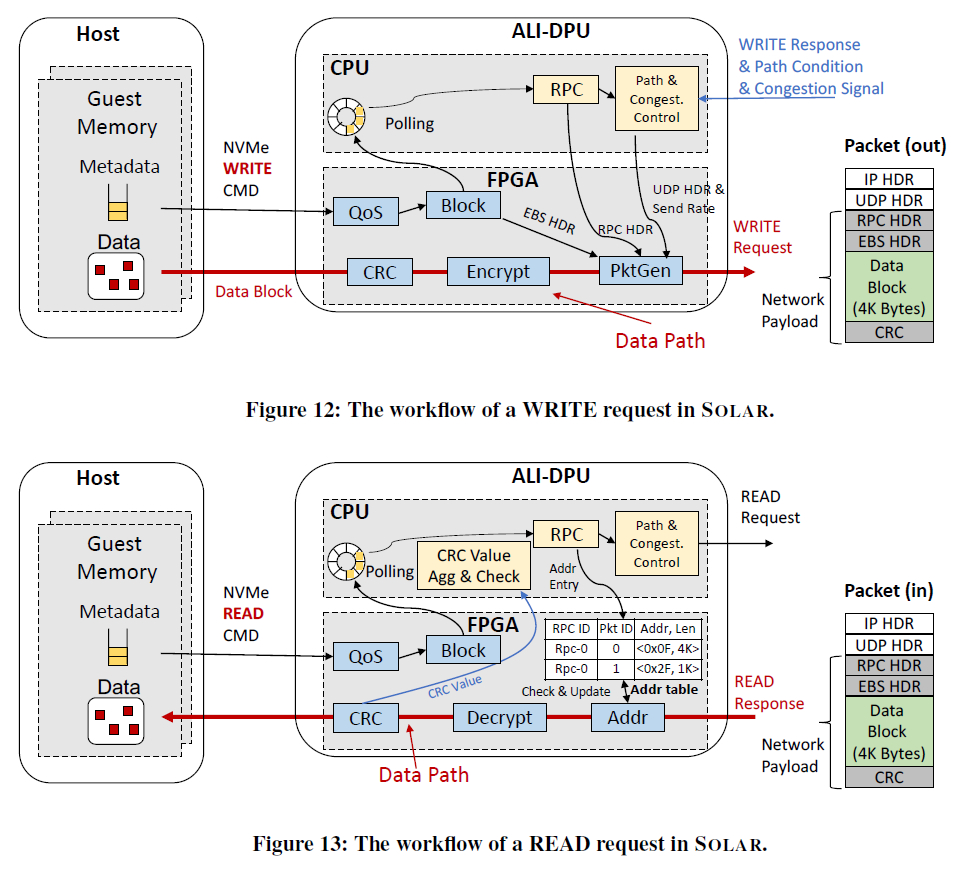
- 写操作过程:QoS获取服务信息,Block获取物理地址,CPU轮询以发起RPC请求,将UDP、RPC报文头生成好。同时与数据合并发出网络包。【CPU在生成RPC头的同时也准备好拥塞反馈的环境等】
- 读操作过程:与写操作不一样的地方在于,RPC读请求由cpu发出,同时维护一个接受表,等待FGPA处理之后的响应。
- CRC的聚合和检测由cpu完成,(FPGA的比特翻转问题难以保证正确性,因此只为每个小段进行CRC计算)。利用了CRC32的递归特性CRC(A^B)=CRC(A)^CRC(B)。
SOLAR的经验
- 从PCIe3.0到PCIE4.0花了十年,但是网络速度却从10Gbps涨到了100Gbps,因此在未来跳过PCIe仍将是重要的
- 将巨型帧的大小从8k降到4k以缓解拥塞,以及使用per-packet ACK来进行拥塞控制
- 将弹性存储系统整合进DPU对于边缘网络等有bare-metal cloud的情况依然能起到一定作用